Location Attestation: Crowdsourced Cross Validation
IP Available Code
Patent
Title: CROSSVERIFICATION OF DATA CAPTURED BY ACONSUMER ELECTRONIC DEVICE
Pub . No: US 2018 / 0189345 A1
Publication Date : Jul . 5, 2018
Status: granted
Patent
Title: SYSTEMS AND METHODS FOR VERIFYING A DEVICE LOCATION
Serial No: 17/479,783
Filing Date : September 20, 2021
Status: Pending
Code: functional reference code natively implemented Android code and a Node.js server-side implementation
Background
Determining the location of a device on which a capture application (or any other application for that matter) is running is a surprisingly complex problem. While mobile operating systems provide an application access to a device’s location (pending a user’s permission to do so), the location itself can be altered by either physically spoofing the location signal received by the device or, a far more prevalent approach, by circumventing the operating system’s software. While root-detection measures can be taken, we have to assume these are imperfect. For the purposes of the methods in this section, we assume a device has been rooted or jail-broken successfully, and in a way, which bypasses all known detection mechanisms.
Dataset Based Approaches and Limitations
Third party providers allow reverse geolocation lookups whereby you can query for the location of a WiFi network or cell tower using its unique identifier such as BSSID or LAC/MCC. These queries work well where there is a large prevalence of connectivity but has a number of drawbacks:
- Attestation is not possible where there is no coverage, for example in warzones, or indeed in rural areas of the UK or US.
- The database needs to be kept up to date. It is not uncommon for a device to be connected to a cell tower or WiFi network that is not yet in a database.
- Some networks move location – a person may move to a new house and take their WiFi router with them, causing the dataset to be outdated.
- Lookups are not always possible in countries with strict data protection laws such as Germany.
Cross Validation – Initial Approach
Rather than relying on a centralised database, we propose to gather data from a large number of ‘live’ devices and cross reference these. The initial theoretical foundation for this was set out in this patent filing:
US20180189345A1_crossValidation
Cross Validation – Introducing an Evidence Function
A more sophisticated approach to cross-validation can be achieved through the introduction of an evidence function. In this approach, a first implementation of an algorithm works by setting a baseline score, and then adding or subtracting from it according to evidence for and evidence against an environment. An “environment” consists of cell towers and WiFi networks. Further iterations of the algorithm may extend the environment to include readings from detectors such as the barometer or light meter.
Evidence in favour of the environment is attained by searching for captures from other devices in a similar location which are in a similar environment. This is done at the time of verification. So “a search” means looking for capture events in the server’s database. A ”similar location” is defined not only in space (e.g. 50 metres away) but also in time (e.g. 1 month ago). A “similar environment” means that the device is connected to the same WiFi network or cell tower. The physical location is taken from the GPS coordinates provided by the device, and time provided by the device’s clock.
Evidence against the environment is other devices in a similar environment but a different location. Here a different location relates to a different physical location at a similar time. We do not penalise for devices in a different environment in the same location (e.g. connected to a different cell tower but at the same physical location and time).
Example 1: Alice takes a photo in Oxford city centre on January 1st 2021 while connected to cell tower A. If Bob took a photo at Oxford train station on January 3rd while also connected to cell tower A, it would provide evidence that Alice’s environment is trustworthy. If Charlie took a photo in Summertown on November 15th 2020 while connected to cell tower A, this would provide evidence for Alice’s environment, but not as strongly as Bob’s. If Chuck took a photo in Oxford city centre on January 1st 2021 while connected to cell tower B, trust in Alice’s environment would remain unaffected.
Example 2: Now suppose that Mallory took a photo in New York City on January 1st while connected to cell tower C. Alice, Bob, and Charlie all took photos in January while connected to cell tower C, but they were in the UK. These all provide evidence against Mallory’s claim of the environment location being New York.
Evidence functions
A location distance, d, is measured as the Euclidean (AKA straight line or Pythagorean) distance from point A to point B. A distance in time, t, is measured as the absolute difference between two times.
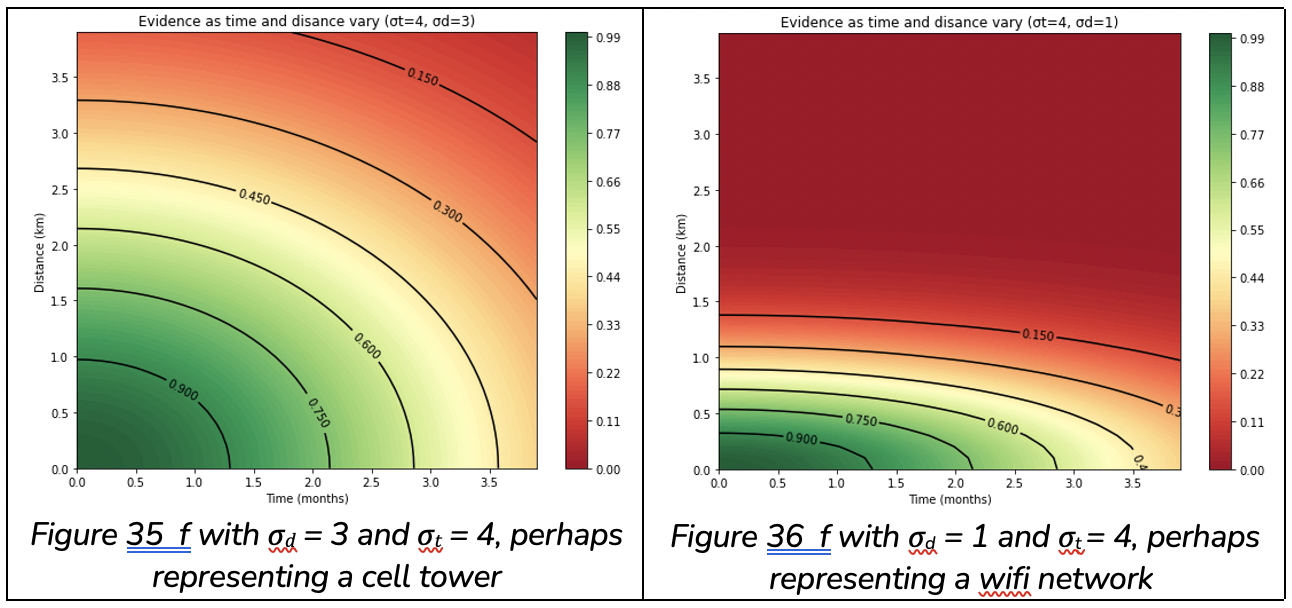
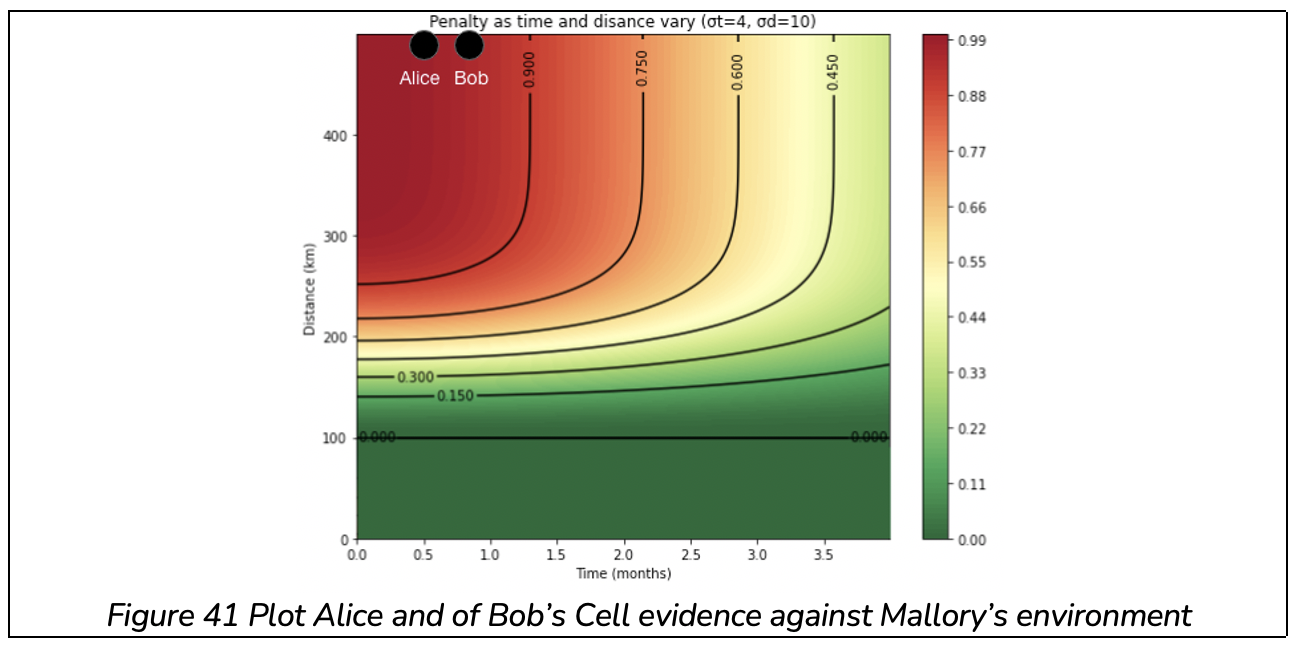
Small location differences and small time differences should bear stronger weight than locations or times which are further away from the capture event. This algorithm makes use of the Gaussian function for the purpose. We use values σdand σt to adjust the strength of the decay for distance and time respectively. This plays the same role as variance in a Normal distribution.
Evidence in favour
We define the function f(d, t, σd, σt) for calculating the positive impact of a device in the same environment. It returns a value between 0 and 1 where 0 is weak evidence and 1 is strong evidence. A small time and small location difference yield a number close to 1, and a large time and or large location distance yield a number closer to 0:
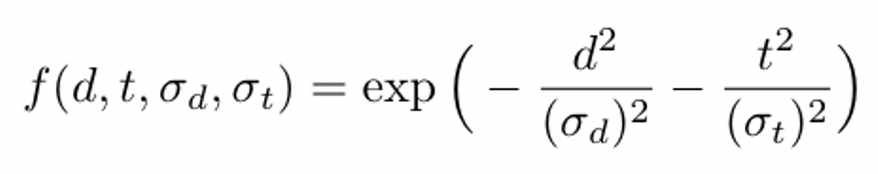
Evidence against
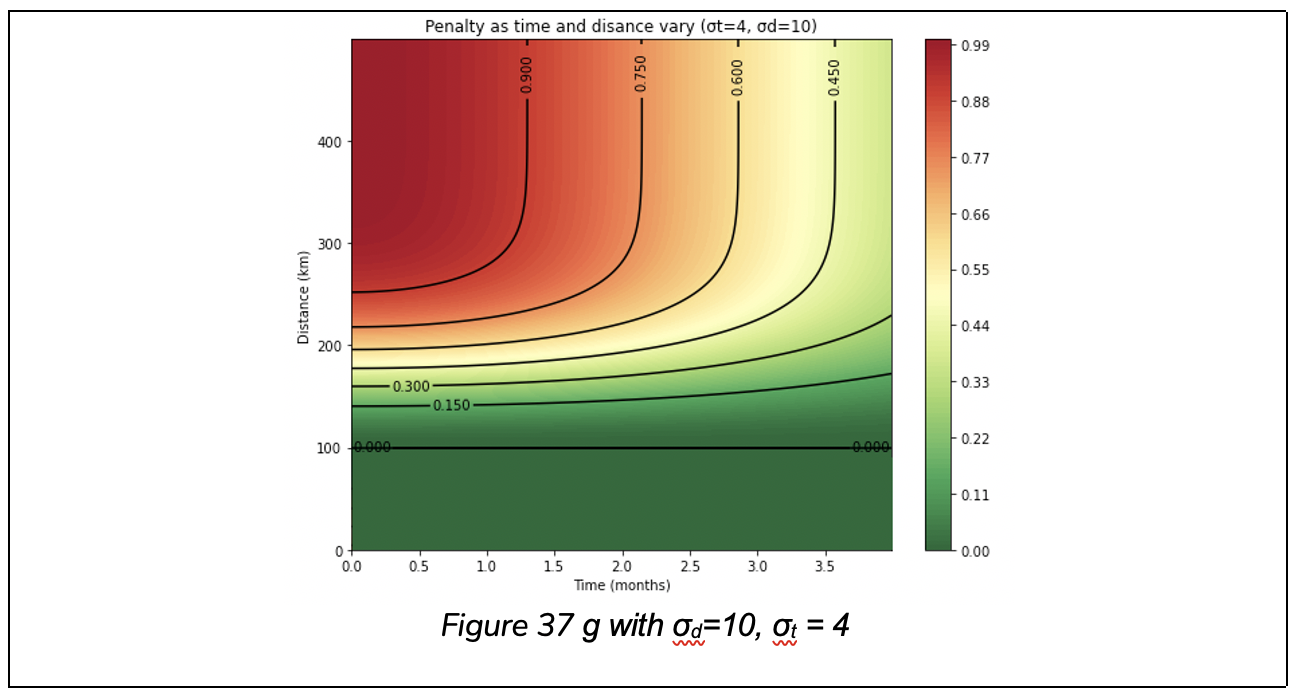
The function g(d,t,σd,σt,μ) calculates the negative impact of a device in the same environment. A large distance yields a number close to 1 and a small distance yields a number close to 0. But we also include an “exclusion zone” which is an area of leniency. For example, we may decide to not incur any penalty for a distance less than 50km. This exclusion zone is denoted μ. Like with positive evidence, we also take time into account, so a different location at the same time is stronger evidence against an environment than a different location with a time difference of 2 years.
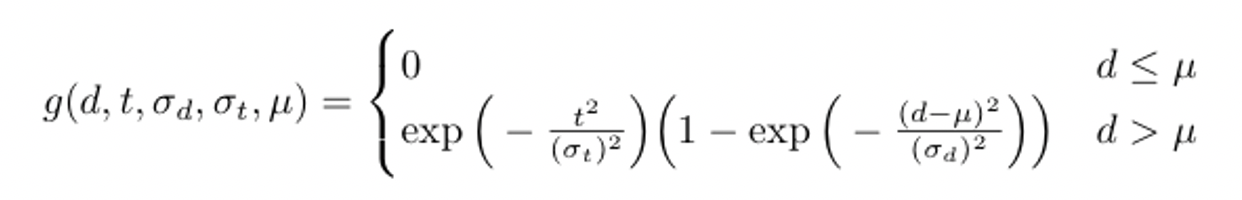
Overall score
The evidence functions f and g provide results for single sensor readings. We are now in a position to define a third function S(d, t, σd+, σt–, σd+, σd–, μ) for the overall score, which combines all sensor readings from all devices, and has range 0 to 1. Here d and t are vectors containing location and time distances of devices in the same environment. σd+, σd–,σd+ and σt– are vectors of location and time decay strength for each reading. This allows us to have a quick decay for WiFi networks and a slower decay for cell towers, accounting for the fact that cell towers cover a larger region. μ is the vector of negative evidence exclusion zone for each sensor reading, which again allows different leniency for cell and WiFi networks.
Taking the example above with Alice, d and t would be the location and time distances between Alice and Bob, Alice and Charlie, and Alice and Mallory’s devices and σ and μ are set according to whether the sensor for each reading is cell or WiFi.
Each of the pieces of evidence from f and g are normalised by taking their arithmetic mean (average) but with (n + 1) devices. This is so that evidence is not biased by the fact that either a large number or small number of devices are present in the environment. In effect this means that if there are n devices providing evidence, each would get a weighting of 1 / (n + 1).
If there’s a single supporting capture, its weight is 1 / (1 + 1) = 0.5, so it is damped to half of its original weight. If there are 100 supporting captures, the weight would be 100/(100+1)=0.99. This means that the more evidence we have available, the more confident we can be. With a small set of evidence, it’s not possible to attain full confidence.
We use a value β as a baseline score. This represents the confidence we are willing to give an environment without any evidence. If β is 0.7, then we can add up to (1 − β) = 0.3 for positive evidence and remove up to 0.7 for negative evidence. Thus, with the lack of any other devices in the environment, we obtain a score of 0.7. With strong evidence in favour of the environment the score can increase to 1, and with strong evidence against the environment it can decrease to 0.
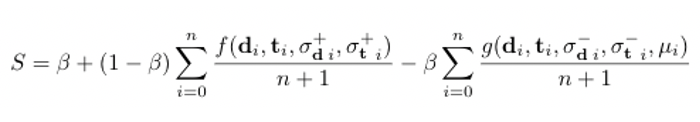
In words this can be expressed as: score = baseline + (evidence for) – (evidence against)
Worked examples
Let’s work through a scenario similar to example 1. The map in figure 4 shows locations and times of captures of three images. It includes the WIFI and Cell Towers that the devices were connected to in each case. We wish to verify Alice’s capture environment using Bob and Charlie’s evidence.
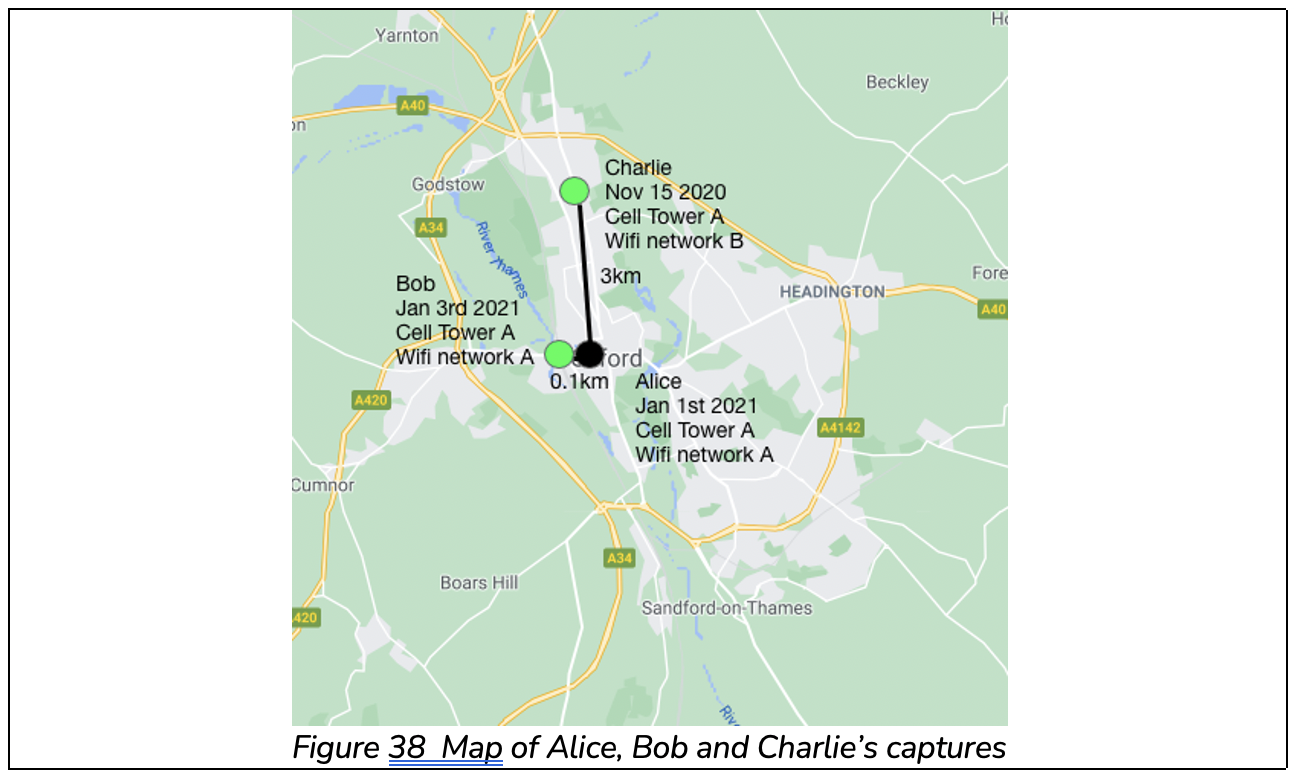
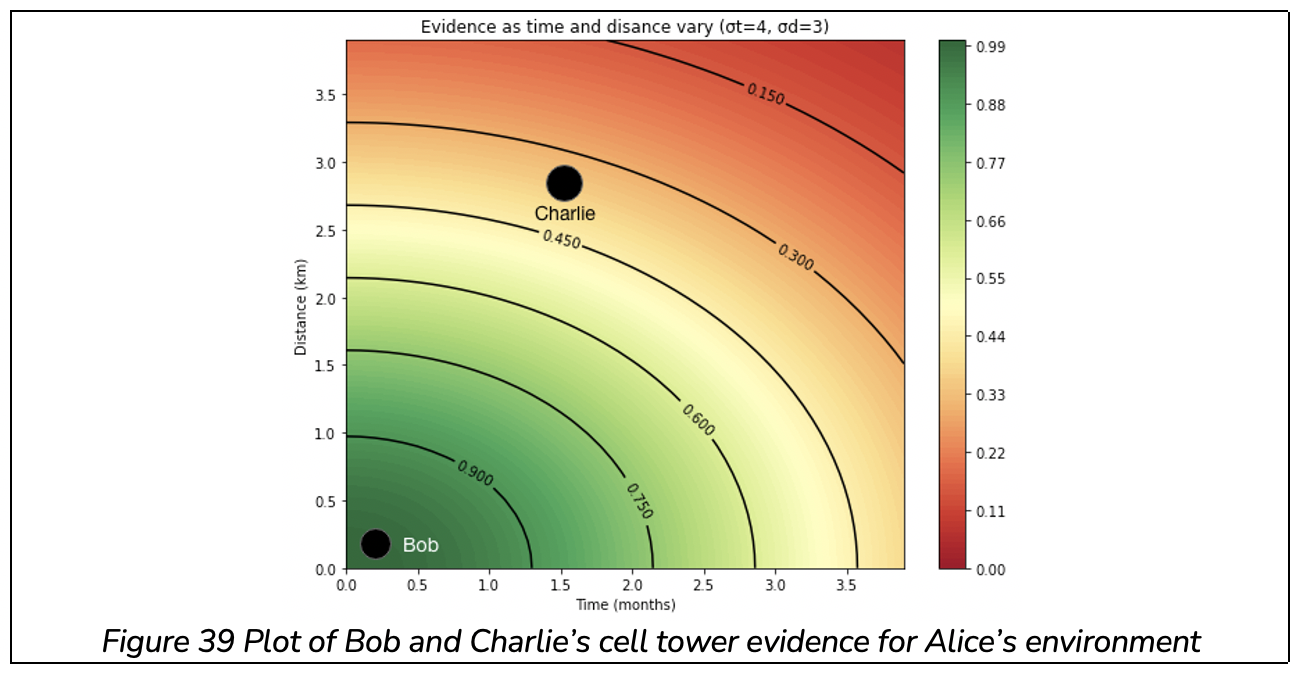
The cell tower evidence from Bob is around 0.99, and from Charlie is around 0.32.
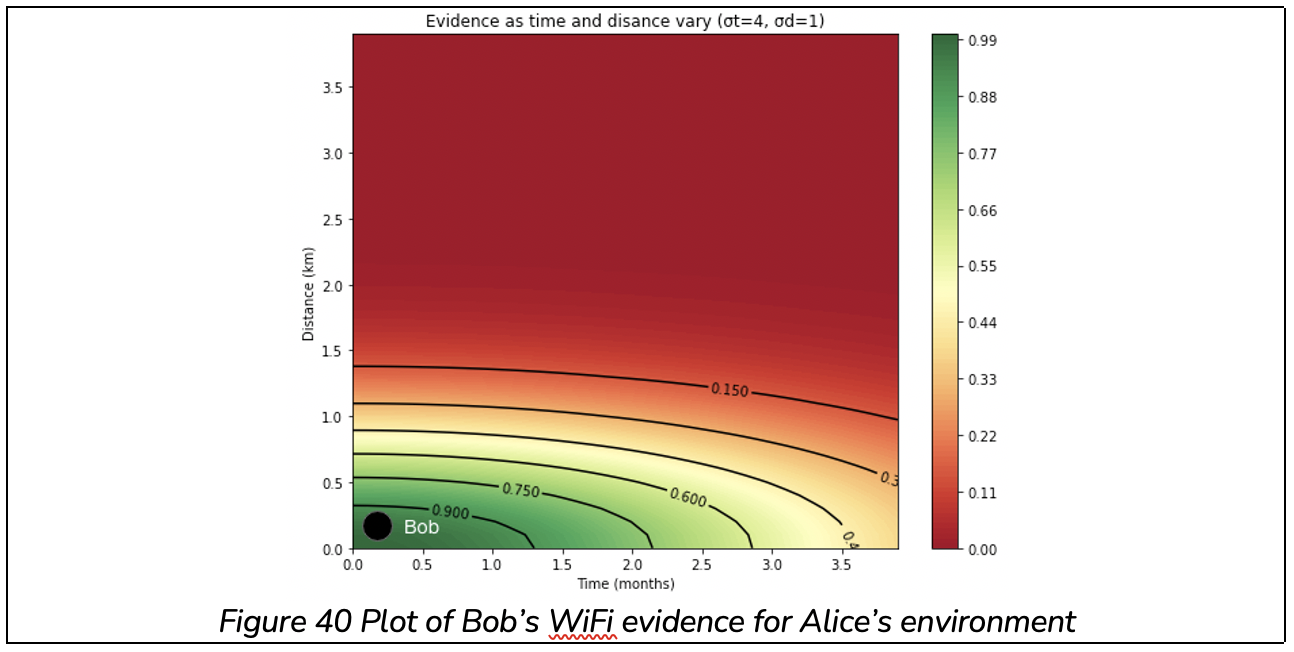
And Bob can provide WiFi evidence, but Charlie cannot. Bob’s evidence is around 0.98.
There is no negative evidence for Alice’s capture since Bob and Charlie’s distances from Alice are within the exclusion zone.
Let’s start with a baseline of 0.7. Then we have:
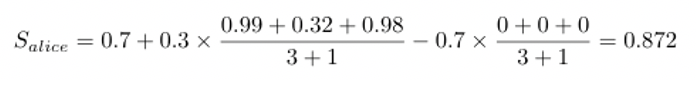
Now let’s take an adversarial case. Mallory has a spoofed environment and claims to be connected to Cell Tower B while capturing a photo on January 1st 2021 in Edinburgh (500km from Oxford). Alice takes a photo in Oxford on January 15th 2021, Bob takes a photo in Oxford on December 1st 2020, both while connected to Cell Tower B.
Alice and Bob’s captures provide 0 evidence in favour of Mallory’s capture since their distance from Mallory is so large. But they will provide around 0.98 and 0.94 against the capture.
Then Mallory’s score is:
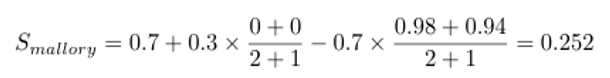
Increasing trust in areas with low coverage
One key drawback of the algorithm outlined so far is that it requires enough users to bootstrap trust from. It’s been shown that in certain well-populated areas such as Bath and London, the algorithm already works. But in less densely populated areas, or those with less photographic interest, it will take time to build a dataset sufficient to derive an acceptable level of trust. Further work has been done to support these areas through a mechanism dubbed ‘network hopping’. This work will be made available once these improvements are added to the patent.