Rebroadcasting Detection: Focal Length Mapping
IP Available
Code
Working code implemented natively in Android and iOS and tested on a wide variety of devices. Server-side implementation in Node.js.
Patent Title: FLAT SURFACE DETECTION IN PHOTOGRAPHS
Pub . No: US 2021/0067683 A1
Pub . Date: Mar. 4 , 2021
Status: Granted
Introduction
An “analog hole” or “rebroadcast attack,” are common terms for subverting provenance systems by capturing an image of a photograph or computer screen.
While such methods may seem rudimentary, they can nonetheless be very effective, and the fact that they can be executed by an unsophisticated user, only increased the importance of developing the means to negate such attacks.
Preliminaries
When an image is captured, a 3-dimensional scene is transformed into a 2- dimensional image. Additionally, the visual representation of depth is emulated through the intensities of the scene’s respective colours. However, on capture the focal point is determined on device.
In which, the focal length is agnostic to the scene’s colour intensities, but rather the distance between a point and device. This means, that the device is able to store a reference to its relative distances to a set of foci. This is achieved by determining the convergence, or divergence, of light on the convex lens attributed by the camera’s parameters.
Now since, a pre-captured image has reduced a scene to 2-dimensions, and the colour intensities hold no 3-dimensional value. It can be concluded that to classify a manipulated scene, all that is required is to classify a flat surface presented in the scene.
Focal Length
The focal length is a measure of how strongly the system converges or diverges light. A positive focal length indicates that the system converges light, while a negative focal length indicates that the system diverges light. A system with a shorter focal length bends light more sharply, bringing the scene into focus with a shorter distance. For a scene that is further away a larger focal length is attributed.
In consumer imaging, a positive focal length is used which is in the range [0, ∞).
Proposal
The proposed method of investigation is to utilise the focal length of the scene to classify whether the captured scene contains a flat surface. In order to do so the focal lengths of multiple foci points are obtained. These data points are then compared between each other to determine whether the captured image contains a flat surface. The focus points Serelay extract on capture are illustrated in Figure 2.
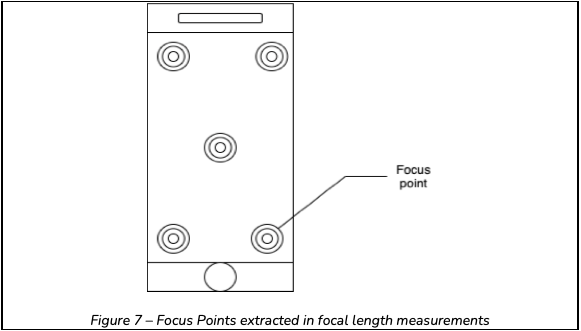
As illustrated in Figure 7, the focal lengths are determined at the following foci: ● Centre
-
Top left and top right
-
Bottom left and bottom right
By extracting the given points above, it allows a holistic capture of the focal lengths which are then later compared.
Assumptions
Obtaining the focal length at various different foci points, allows the device to store distances to different objects in the same scene. For example, if the device was in frame of a spherical object, the foci will have different focal lengths across the surface of the object. However, if the object was planar the foci points will converge to the same focal length, thus giving a clear indication that the scene contains a flat surface.
In theory, the focal lengths for a planar object are the same. But one needs to consider that both the objects and device are governed by three degrees of freedom. Therefore, the view/capture angle of the object’s surface, relative to the device, governs the focal length, as illustrated in Figure 8.
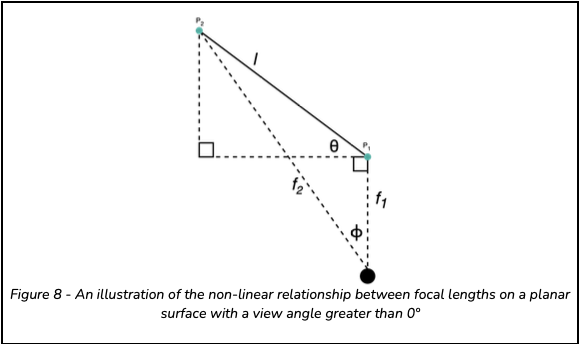
For a flat surfaced object, with length l, transformed clockwise by θ about the z − axis, the focal lengths f1 and f2 are related as follows,
![]()
From this equation, it can be seen that the relationship between the two focal lengths, f1 and f2, is nonlinear. Additionally, this equation holds in both the x−axis and y−axis as well. Given this, an interpolation of this artefact is difficult in scenes where a majority is 3-dimensional, with a minority being the given flat surface. Hence, the need to explore a Machine Learning Classification approach.
Trained Models
The following models were trained and tested (along with their associated hyper- parameters where applicable),
- Support Vector Machine (SVM)
- k (kernel): Radius basis function
- Logistic regression
- Neural network
- Hidden layers: 1 (100 neurons) o Optimiser: Adam
- Learning rate: 0.001 (constant)
- Naïve Bayes
- Nearest Neighbour
- K-nearest neighbours
- Neighbours: 5
- Weight: Uniform
Dataset Overview
To comply with Serelay’s image attestation standards, and to avoid heavy processing on the mobile device, the dataset comprised of only focal length data points which are then processed off device and post capture. The mobile device was forced to auto-focus on several interest points. In which the focal lengths were extracted in addition to the captured image’s focal length. A single image data point is as follows,

where x is the input set.
A sample size of 206 was obtained, and a 70/30 training/testing split was applied, in additional to a pseudo-random shuffle. Additionally, it must be noted that of the 206 samples, 119 were images of Flat Surfaces and 87 were 3d scenes.
Results
To avoid skewed training, the four models used in this research were cross validated three times, this included multiple re-shuffles of the dataset. Where applicable the models’ results are tabulated for the three iterations or summarised as an average of the results.
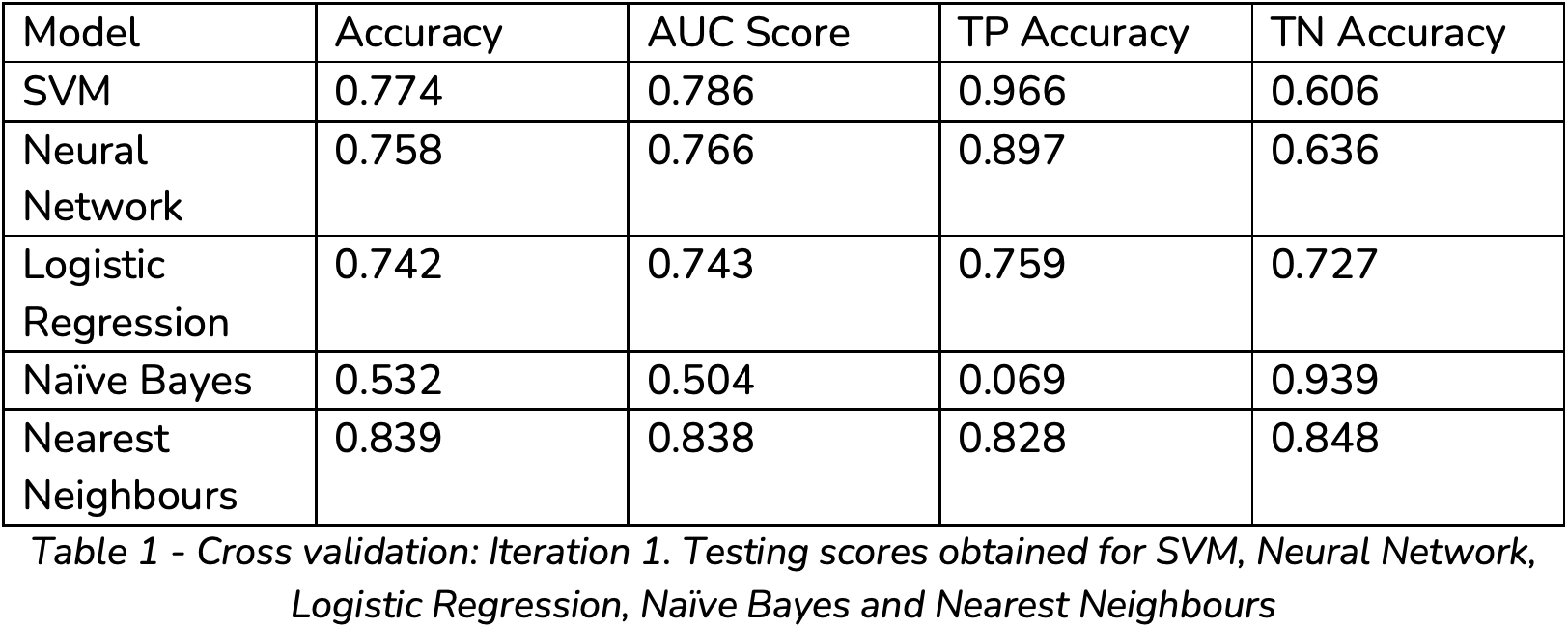
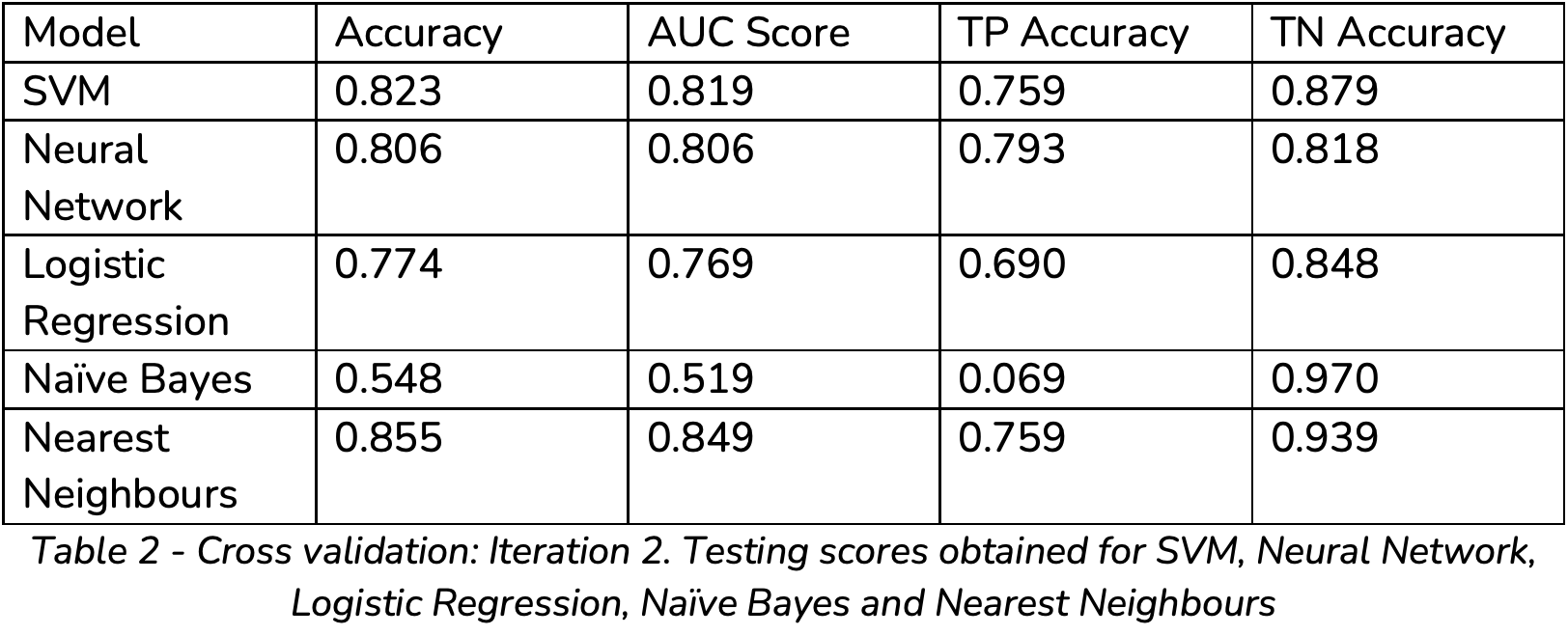
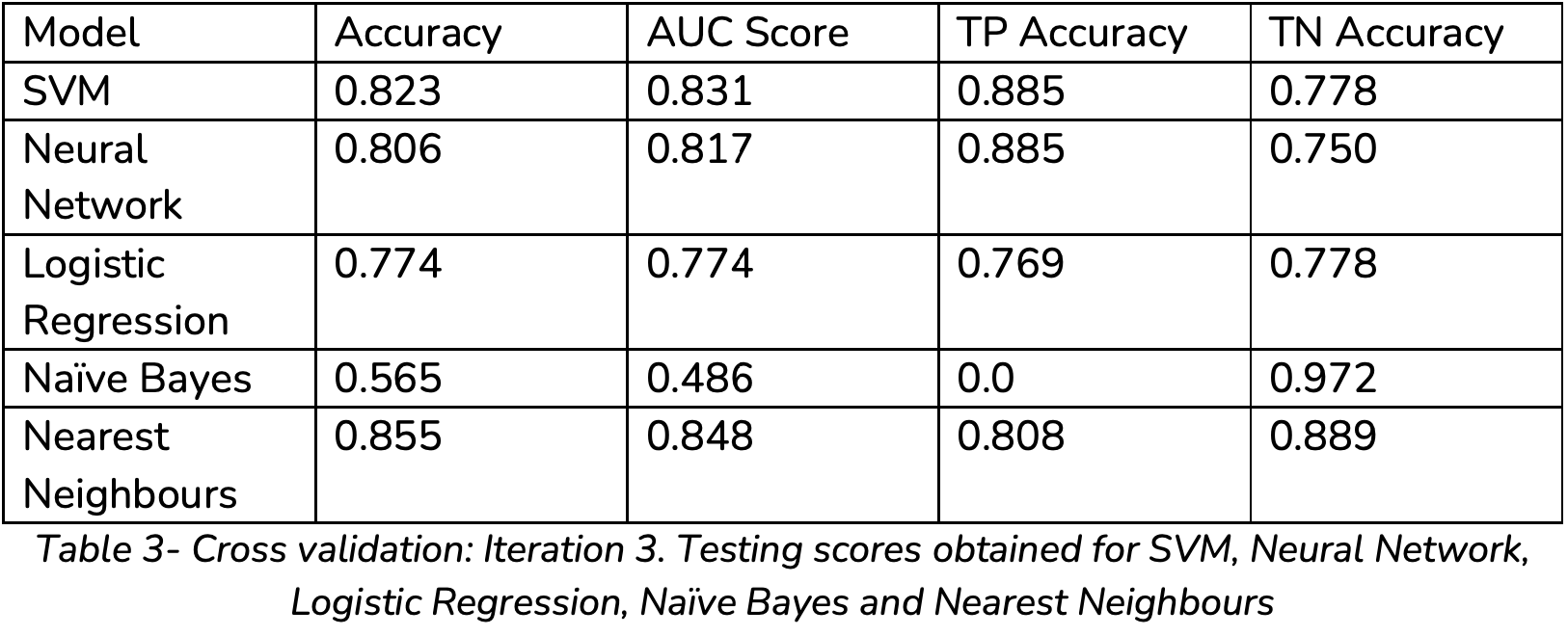
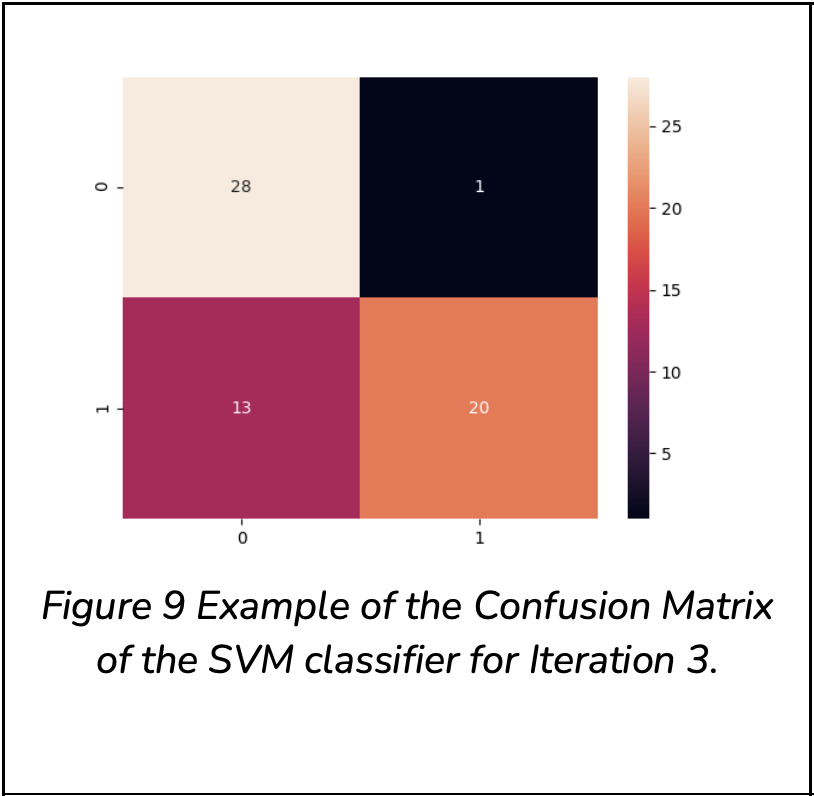
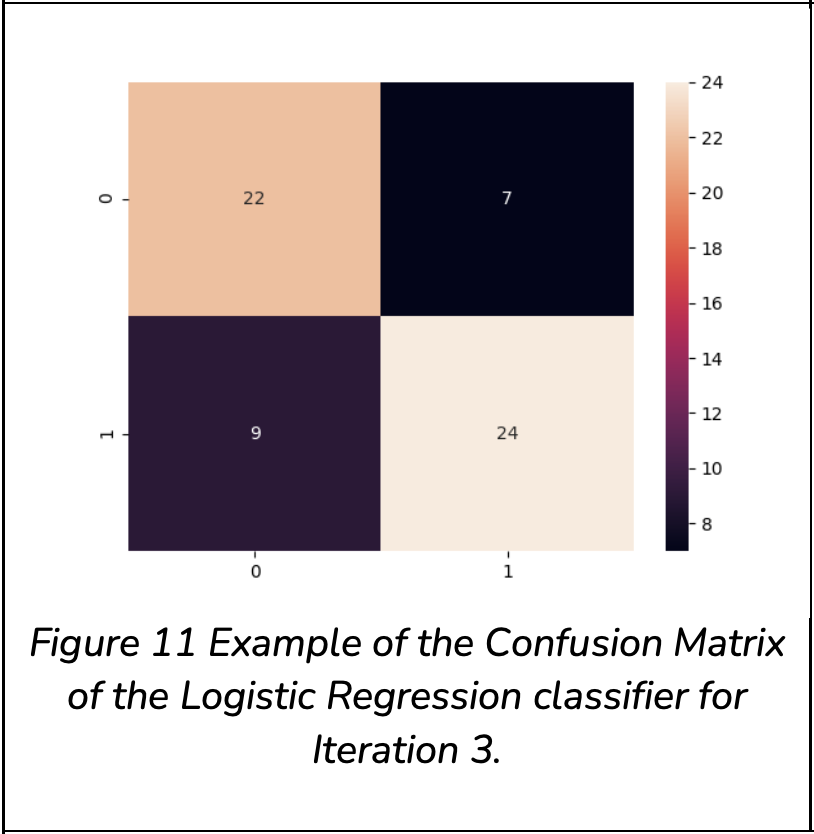
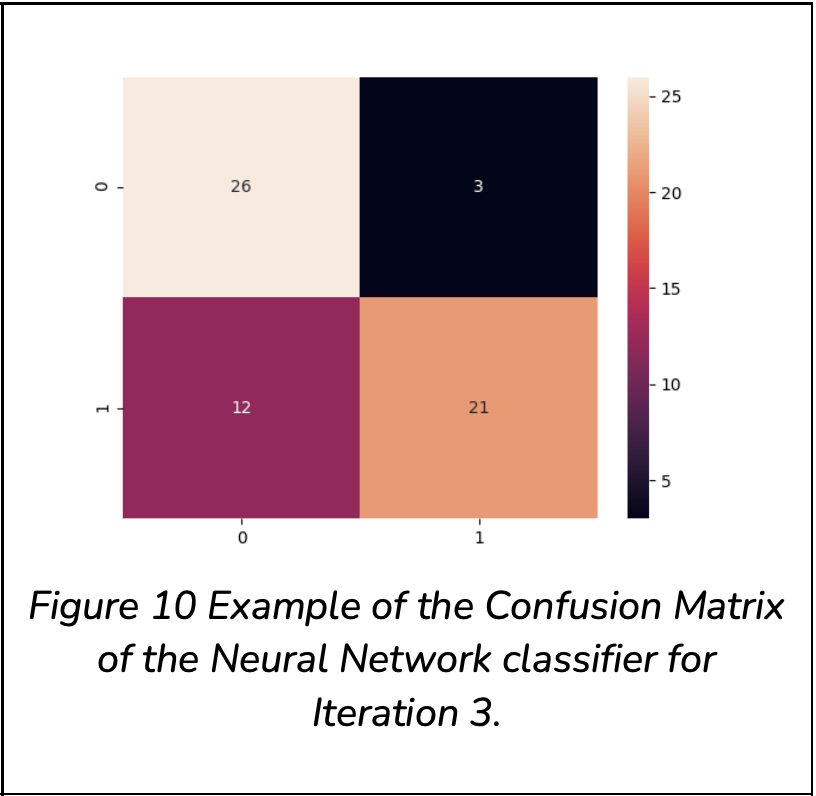
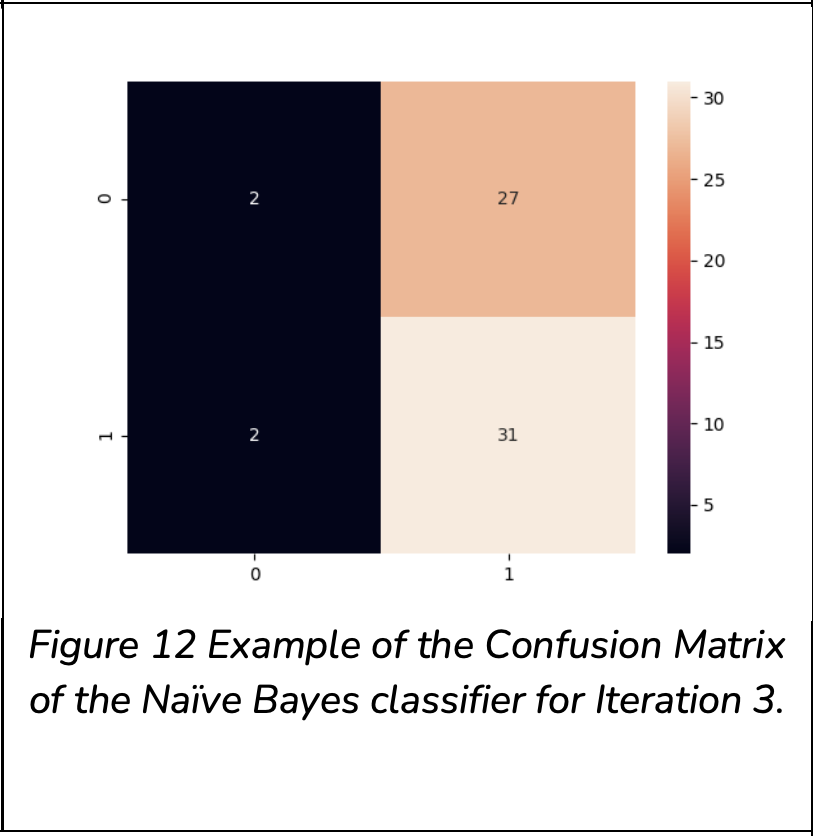
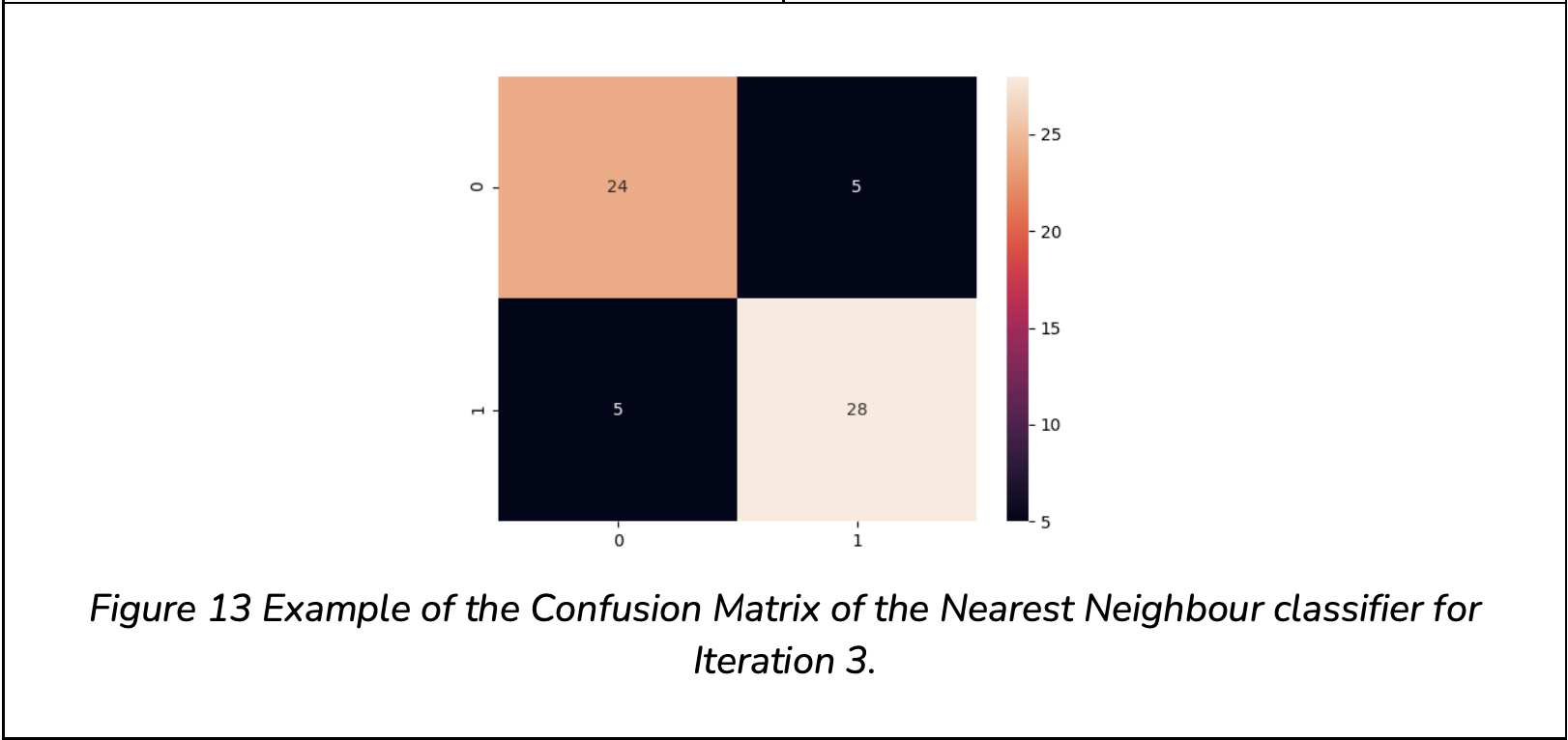
From the results obtained, the following can be noted:
-
The Naive Bayes algorithm poorly performs to classify a Flat Surface. This is because its true positive accuracy only ranges between0 and 0.069. Hence, this algorithm was disregarded from further investigation.
-
From the performance tables (Table 1, Table 2, Table 3) it can be seen that the Nearest Neighbour algorithm has bias towards classifying images as Non- Flat, based on the notable difference between the True Positive and True Negative Accuracy, with an average of 0.8 and 0.88 respectively.
-
From the prior tables it can be seen that the Nearest Neighbour algorithm has bias towards classifying images as Non-Flat, based on the notable difference between the True Positive and True Negative Accuracy, with an average of 0.8 and 0.88 respectively.
-
SVM has a bias towards classifying images as flat, which is noted by its higher True Positive score in comparison to its True Negative score.
-
SVM has a relatively high separability, but a concern does arise as it has a high sensitivity to cross validation as its scores fluctuate considerably.
-
SVM, in comparison to the Neural Network, has a higher accuracy, as well as a higher separability.
-
Logistic Regression is stable. However, in comparison to SVM and Neural Network, it has a lower accuracy and separability.
Implementation
It must be noted that as per the implementation details outlined in the patent documentation, the focal length range extracted for Android and iOS are different. For iOS devices, the focal lengths are inherently normalised between 0 and 1, as opposed to Android devices where the focal length are measured in Dioptres. Hence for this reason, two models were trained and deployed to cater for both platforms. Furthermore, no pre-processing was performed.
Limitations
The following is a list of potential issues that may arise in the classification process:
-
Scenes that have naturally occurring flat surfaces, may be classified as an illegitimate image – resulting in false positives.
-
The dataset that was used to train the models for the Android Implementation lacked or had no extreme values such as ∞, this is a major concern as the ML model would become unstable for scenes that hold these values.
-
Extremely far scenes from the camera, are likely to capture focal lengths of ∞ which may result in a misclassification.
-
Dark scenes are also likely to capture focal lengths of ∞ which may result in a misclassification as well.
Conclusion
In conclusion, we have shown that it is possible to identify when an image contains a flat surface using focal lengths. Furthermore, we have developed a novel solution that integrates SVM with focal length data to classify an image accordingly.